Post-training will not get us to fully capable agents. These techniques have produced genuinely impressive systems, but they’re brittle at the edges. We’ve all been there: you vibe-code an amazing app, then push the agent toward something less familiar (Angular instead of React, Bazel instead of pip) and it starts falling apart.
This was supposed to be a post about a cheap continuous-learning technique for agents. It became a post about why my first attempt at building one didn’t work. The short version: my LLM judge produced feedback that sounded useful but didn’t track whether the agent actually got the answer right, and when I cheated and fed ground truth to the judge directly, the resulting skills improved performance on the questions I was training on but didn’t transfer to held-out ones. But the why turned out to be more interesting than the system itself. This is a long post, so settle in.
What’s the Problem?
Now, clearly, post-training has gotten remarkably good. RLHF, RLAIF, Constitutional AI, DPO. Pick your favorite. These techniques that turn a base model into an instruction following machine have produced agents that are genuinely useful, well-calibrated, and surprisingly capable across a wide range of tasks. The huge success of Claude Code should be a clear indication of this. I don’t want to understate the progress over the last few years. It has been really amazing!
But I want to make a claim that I think is underappreciated in the other direction.
I want to be clear: This isn’t a criticism of the research direction. It’s a structural argument about what post-training can and can’t do.
Here’s the thing: Post-training optimizes a model’s behavior against a distribution that is fixed at training time. Once the model is deployed, the distribution of real-world situations it encounters is larger, weirder, and more specific than anything that can be covered in a training set. The long tail is the problem.
The world generates new complexity faster than training sets can cover it. That’s structural. It doesn’t get fixed by more data or a bigger training run.
Okay, So Write A Better Prompt…
The obvious response is to write better prompts.
We should just add explicit instructions for how to handle novel architectures, look up documentation for infra that is novel, how to navigate unfamiliar code bases. This works up to a point and has actually seen some pretty good improvements as well (e.g. Claude Skills).
But the failure mode is still predictable: you start with a reasonable system prompt, add a line or new skill for each failure mode you observe, and after six months you have a library of 2,000-word behemoth prompts. This set of prompts may cover all the cases you have seen but still fails in novel ways under new conditions and is a pain to maintain.
But there’s a deeper problem: even a perfect prompt can only encode *general* guidance. “When root-causing a bug, check the call stack before reading individual functions” is useful. But what you actually need, in a specific encountered situation, is specific: “in this async event-driven architecture, race conditions typically show up as missing await statements two levels below where the error surfaces.” That’s not general knowledge. It’s earned knowledge, from real experience with this type of system. And this type of information would be an absolute technical nightmare to write and maintain.
What Should We Do Then?
So we can’t get there with training because we’ll always see out-of-distribution situations in the real world. And we can’t prompt our way there because it turns us into iterative prompt tweakers that play whack-a-mole with failure cases. What’s the solution?
Well here’s my thinking: Reinforcement Learning (RL) may have an answer for us here. In RL, you have a policy, an environment that produces rewards, and an update mechanism that tries to improve the policy given the environment. The beauty is that you don’t need to specify how to improve. You specify what “good” looks like, and the system figures out the rest.
What if we applied this to the agent’s operational knowledge? Not to the weights but the same underlying principle: observe behavior, score it, update the policy toward better outcomes.
But if we’re not modifying weights, what is our policy? The “policy” here is a set of explicit, readable Claude Skill files the agent can load before each task. And the “update” is a separate LLM that rewrites them based on what the data says isn’t working.
This is RLAIF (Reinforcement Learning from AI Feedback) applied to acquired operational knowledge rather than model weights. Skills accumulate from real encountered situations by the specific user that will care about those skills. The gap between training data and deployment reality narrows over time because the system learns from the specific things it encounters, in the specific environment it operates in.
The goal of these skills, then, should be to encode the knowledge that emerges from real failures and real successes. Things like technical approaches that worked, reasoning strategies that caught things other approaches missed, domain patterns specific to the actual work being done.
The RL Skill Architecture
Okay, here is my proposed v0 architecture. I’ll run some tests on this to see what works and what we need to modify.
I want to build a system that has the following loop for some benchmark we will use to performance metrics (not for the RL signal):
- Run an epoch of Claude Code on some LLM agentic benchmark
- Run the evaluator on the rollouts from that epoch
- Run the evolver on the results from the evaluator only, not looking at the full rollouts or the benchmark results, to create new skills
- Repeat
We will be using Haiku for the agents, the evaluator, and the evolver. The agents will run in Docker containers to maintain isolation and protect my computer from errant agents.
For our benchmark, we’ll use GAIA with the hope that we can iterate quickly and there is enough difficulty variance within the dataset that we can see actual improvements over time.
That is it. For this first iteration, my goal is to keep things as dead-simple as possible.
Importantly, we don’t need any verifiable reward for this system. We just need tasks that we trust the evaluator’s judgement. We’ll see if that judgement is actually helpful. There are some known pitfalls with using an uncalibrated LLM that we’re likely to see (e.g. verbosity bias). But let’s first get a baseline and go from there.
The LLM evaluator will see the whole rollout and be judging on the following criteria:
- Helpfulness
- Accuracy
- Reasoning Quality
- Tool Selection
- Knowledge Application
The LLM will be tasked with giving each criteria a score from 1-10. We will likely have to change this in the future as LLMs are notoriously bad at giving calibrated numerical rankings and scoring in a vacuum. But to keep things simple, we will start here.
The evolver will receive the full suite of scores as well as explanations for those scores when performing the skill generation and evolution.
One other thing to note: Evolution notes are embedded in skills as comments. These are stripped before the agent sees them. The evolution agent can see why each piece was added in previous cycles and act as institutional memory in the document itself. We’ve all accidentally vibe coded away important pieces of code or prompt because the coding agent just didn’t have the context for why a specific block was important. We want to avoid that here. Without these comments, the system would probably endlessly loop modifying the same prompts with the same modifications.
To make the RL parallels really concrete, I wanted to also explicitly state the mappings from RL to the proposed system:
Actor -> The Agent performing the actual coding actions.
Critic -> The Evaluator Agent scoring the helpfulness, accuracy, and tool use.
Environment -> The container in which the agent can interact + all the tools it has access to + the prompts from the user.
Trajectories / Episodes -> The rollouts from the agent’s conversations.
Policy -> The Base LLM + The Active Skill Files.
Trust Regions -> We reject any evolution of a skill that introduces more than x% change to the character content of the original skill. We’ll start at 30% and modify if needed based on experiments.
To be clear: these are loose analogies, not formal correspondences. The “trust region” check isn’t measuring KL-divergence or providing any mathematical guarantee. Prepending “Do not do any of the following:” to a long skill file is a <1% character change that completely inverts the policy. The “policy” itself has no gradient; updates are discrete rewrites, not smooth parameter changes. But I still think the framing is useful for reasoning about these concepts at a high level, as long as we’re honest about where the analogy stops.
First Impressions
Nothing left to do but give it a whirl. I expect to find many pieces that need modification but lets base those on initial findings. I’m going to run this on a small subset of GAIA to start with to just get a feel for the system and solve any major issues quickly. So, first, what are we testing?
🤔Hypothesis
If we allow an agent to create and evolve a set of skills based on its own judgement of task performance, it will improve its performance over time on difficult tasks.
Okay, pretty straight forward. Let’s run it!
One note: I’m going to be looking at the performance of the same set of 50 questions in GAIA for each epoch to see if they improve over time. These are the same questions that the evaluator and evolver are going to be using to create skills. While this is not a good way to make sure the system is providing general improvements, it is a great way to make sure there is some flow from the reward back to the policy updates. So as a first test to make sure the system is well formed, I’m going to just be looking at a single set of 50 questions. Explicitly: this is a sanity check for gradient flow and nothing more. Once I get clear gradient flow, I’ll use a held out dataset for actual performance eval.
We’re going to do one additional simplification for this initial test. Instead of allowing agents to decide what skills to load, as is part of the Claude Code Skills architecture, we’re just going to force inject the full suite of skills into the system prompt. This will remove the variability that might come from agents deciding whether to load skills or not. Again, in later runs once we’ve verified the base idea, we will add skill loading in.
Epoch 1 will give us a clean baseline without any skills. Later epochs will show us whether the combo of eval + evolve can improve performance. Once we find a stable state, we’ll move on to ablation and seeing if evolution is necessary.
Here are the final results for our first run:
| Epoch | Pass@1 | Eval Score | Skills |
|---|---|---|---|
| 1 | 48% | 5.7/10 | 0 |
| 2 | 48% | 5.7/10 | 5 |
| 3 | 46% | 5.6/10 | 6 |
| 4 | 48% | 5.8/10 | 6 |
| 5 | 52% | 5.6/10 | 6 |
| 6 | 46% | 5.2/10 | 6 |
| 7 | 46% | 6.0/10 | 6 |
| 8 | 48% | 5.3/10 | 6 |
| 9 | 48% | 5.8/10 | 6 |
| 10 | 48% | 5.5/10 | 6 |
🔍Analysis
The first obvious takeaway is that the skills are not improving pass@1. It also appears that skill generation plateaus very quickly. Eval score also does not seem to be effected by new skills.
First of all, we’re not getting improvement even in our regime where we’re primed to overfit. The most surprising thing here, though, is that eval scores don’t improve. Even if skills were not helping to improve pass@1 because they are not directly derived from these scores, I would think evals would steadily increase. But it appears that is not the case.
Digging In
There is a lot that could be going wrong so it’s time to get a feel for how things are working. First, lets look and see if we’re consistently getting the same answers right/wrong or if that is changing over time.
The following is a chart that shows the answers we got correct. Any purple block was answered correctly for the given epoch. White blocks are incorrect.
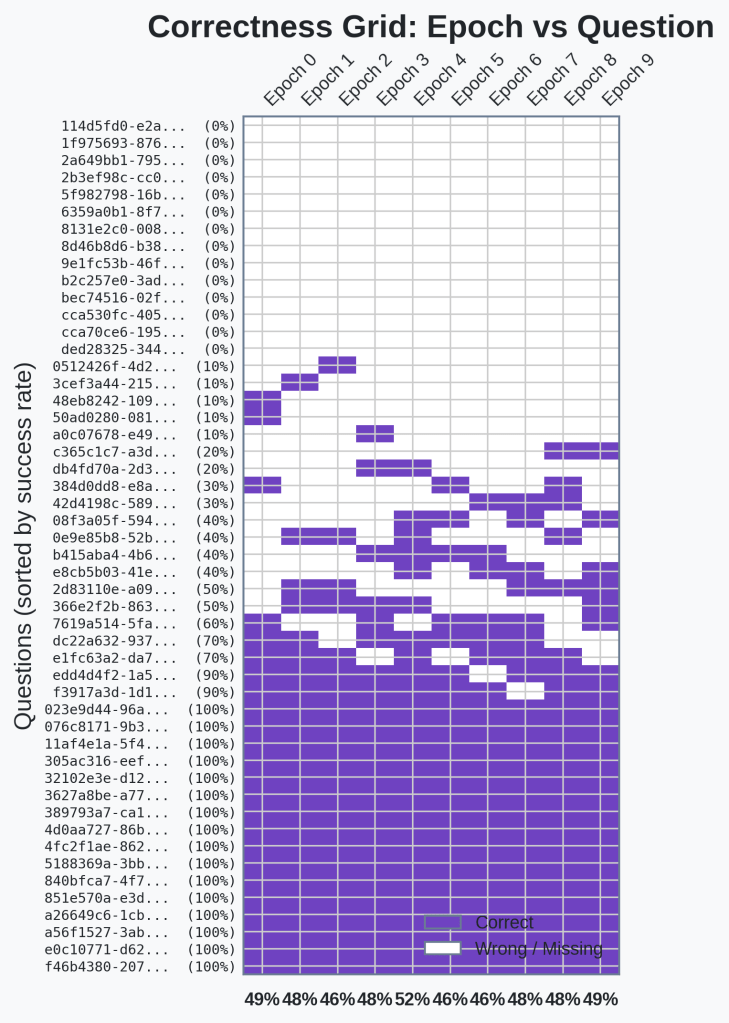
🔍Analysis
Okay, there doesn’t seem to be any pattern here. There are questions we get consistently wrong, questions we get consistently right, and then a suite of questions that are right on the edge of the agent’s capabilities.
It seems from the chart that skills aren’t causing some consistent performance changes for any of the questions.
Okay. Another good sanity check is to see if the eval results actually correlate at all with the actual benchmark results. I created a scatter plot that maps benchmark accuracy to evaluator score on a per-question basis across all epochs (the purple dots). I’ve also included an accuracy rate per eval score bin (the blue line).
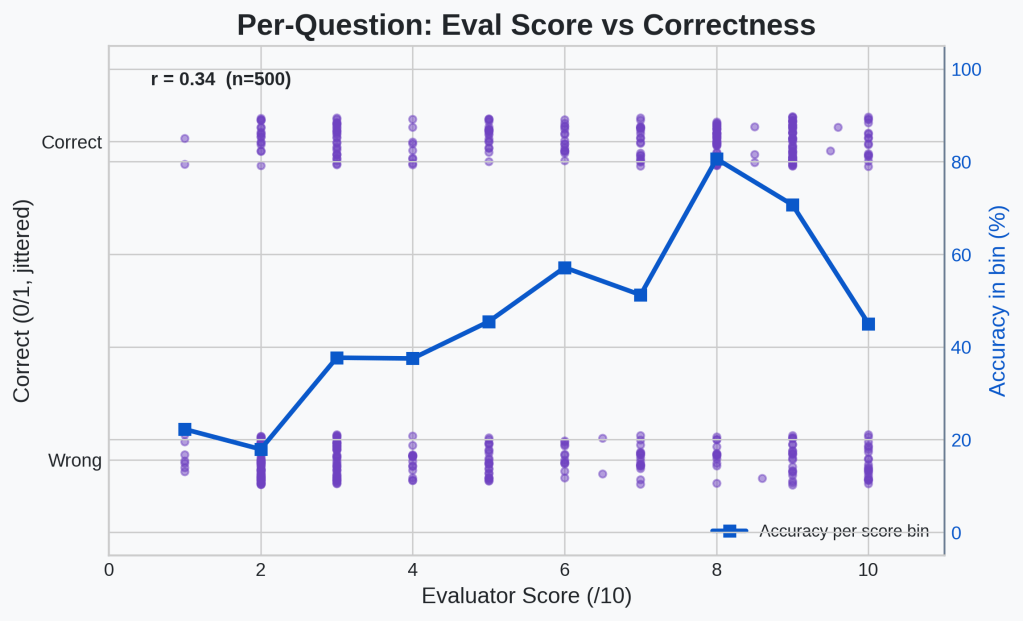
🔍Analysis
The accuracy rate does seem to increase as the eval score increases. We have an r-value of 0.34 indicating positive correlation. The dip at eval=10 is worth noting.
Okay, so the idea that an LLM can give some positive feedback that corresponds to improving performance on benchmarks might hold water. The question is whether this correlation is mostly from the questions that we always get right or always get wrong. Let’s generate the same plot but only look at questions that the agent got both right and wrong at some point in the 10 epochs.
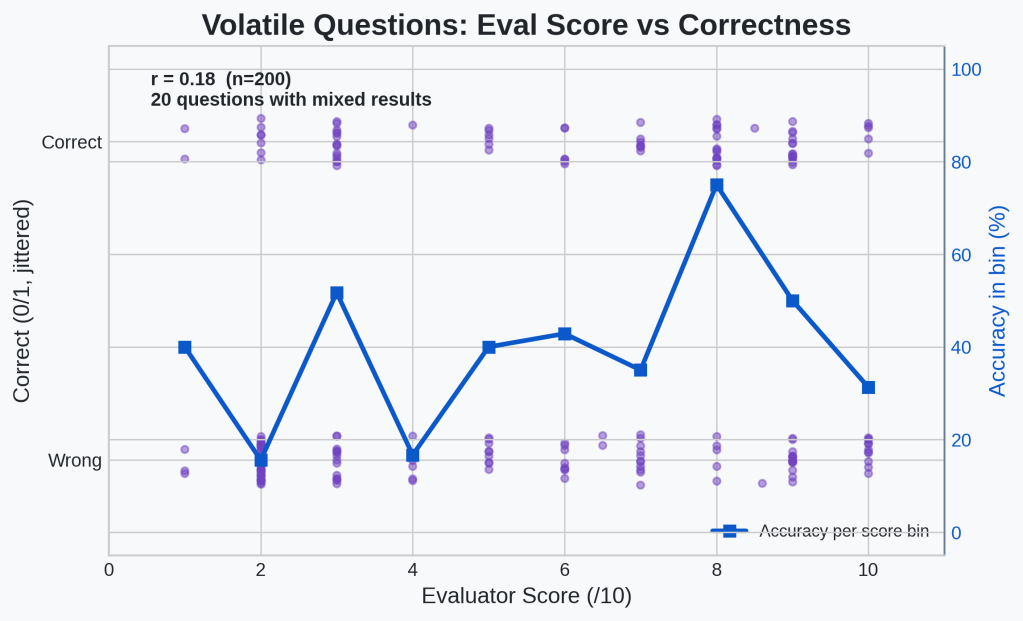
🔍Analysis
On these 200 examples, the positive correlation is much less clear. There is still a positive r-value, this time of 0.18, so there is definitely still positive correlation, but it is much weaker.
Okay, the correlation is very weak on the subset of questions that probably matter. This means that our eval system right now is mostly just telling our system how hard the question is and isn’t really helping to distinguish between successful and unsuccessful attempts of a hard question. That is a pretty clear sign that we need to work on our evaluator. This is not a surprise. As I mentioned above, there are a lot of problems with the simple evaluator setup I have now.
Evaluating the Evaluator
Okay, we have a clear indication that the evaluator isn’t working as intended. But we can perhaps uncover some clear indications of why its not working before we move on to trying to fix it.
One quick thing we can check is whether any of the individual components of the eval are showing better performance. I’m going to recreate the plot from above on the flaky questions but for each individual component of the total eval.
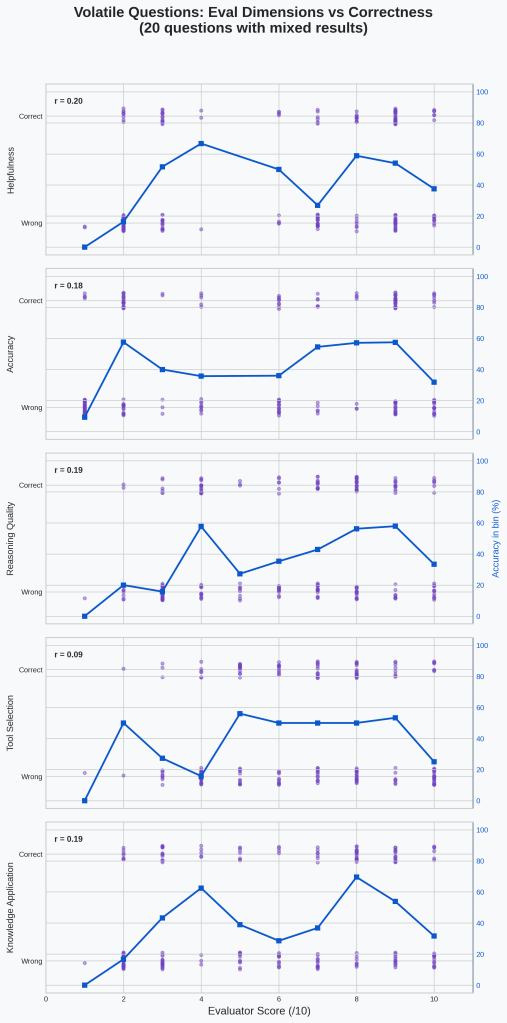
🔍Analysis
R-values are all at or below 0.2. None of them are doing very well. Tool selection in particular is weakest at 0.09 r-value.
Okay, none of the components are particularly useful either. None of the individual components is significantly better than the overall score (r=0.18) at predicting actual correctness on these mixed-result questions.
I’m going to pick a couple of the mixed-result questions and look at the actual rollouts for successful vs unsuccessful results and check the evals as well to see if there is any useful information to glean there.
I created a little script that will print out information about a single GAIA example across all epochs. It only took a few minutes to build. It will put together eval scores (including breakdowns for each of the categories), whether the answer was correct for a given epoch, and the full rollouts for each epoch. I’ll use this to dig deeper into what is happening with the evals.
Okay. I have to be very careful about what I write because whatever I write is on the internet forever and agents might eventually use sources like this to cheat. I can see in some rollouts the agent gives up and starts searching the internet for GAIA question answers, for example. So without getting in to too much detail, the evaluator is often providing what sounds like useful feedback “use multiple sources rather than one source” that may or may not actually lead to a correct answer. This is a common problem in RLAIF: plausible-sounding AI feedback can be systematically uncorrelated with actual task outcomes.
The obvious solution here is to use the actual benchmark performance as input to the evaluator. But that goes against the goal of this system which is to get away from using direct benchmark performance as a signal in our RL system.
The next best solution would be to fine-tune our evaluator on actual task performance and then use that fine-tuned version as the evaluator during our experiments. But I’d like to avoid that if possible as well. Fine tuning a model is not something most people have access to. And I personally do not have the ability to make a fine-tuned Claude model. And it still feels like it’s breaking the rule of our system which is to not use benchmark results as input.
But there is actually another solution that I think makes a lot of sense. The goal of this project is to get a skill system that will work in any prod system. Human labels cost money and require a labeling pipeline. Benchmark results only exist in lab settings. But noisy downstream success/failure signals? Those are practically free in most production systems. Did the CI pipeline pass? Did the user accept the PR? Did the customer reply positively? Did the deployment succeed? Every real system already emits these signals. They’re just noisy. Perhaps there is a route here where the evaluator can take in a noisy success signal and build useful skills from that.
But before we go down that path, it is really important to first make sure the evolution half of the system works. If I don’t do this verification, I will never be sure that some change I make to the evaluation framework is actually working or whether the evolution framework is just broken. We’re removing a confounder.
Drop RLAIF For a Moment
The simplest thing to do here is to just feed in the benchmark results directly as signal to the evolution agent.
Explicitly, what this means is that the evaluator is fed the actual result on the benchmark and the full rollout. The evaluator’s job, then, is to summarize why the rollout was successful or unsuccessful. Again, there are many potential problems with this, the greatest being that the LLM might just hallucinate reasons for success or failure. But we’ll start here because it is simple and see what needs modification.
| Epoch | Pass@1 | Eval Score | Skills |
|---|---|---|---|
| 1 | 46% | 5.0/10 | 0 |
| 2 | 48% | 5.3/10 | 6 |
| 3 | 46% | 5.2/10 | 6 |
| 4 | 44% | 5.1/10 | 7 |
| 5 | 52% | 5.6/10 | 7 |
| 6 | 50% | 5.5/10 | 7 |
| 7 | 46% | 5.4/10 | 7 |
| 8 | 46% | 5.4/10 | 8 |
| 9 | 50% | 5.6/10 | 8 |
| 10 | 46% | 5.2/10 | 8 |
🔍Analysis
We see more 50%+ in this run but that could just be from natural variance. We also don’t see the eval scores going up again. Skills continue to increase over time.
The increase in 50%+ scores is well within the noise of a test with only 50 examples. With such a strong signal coming directly from the benchmark results, if the final outcome is either non-existent or so small that it cannot be distinguished from noise, especially in our setup that is designed to overfit, when we go back to RLAIF, we’ll have no hope of improvement. So we need to make our skill system more robust. Time to dig in again and see what isn’t working.
Evaluating the Evolver
The first thing I want to check is whether there is a clear indication of skills changing which questions we get right. So let’s look at the same block chart to see which questions we’re getting right and wrong across epochs.
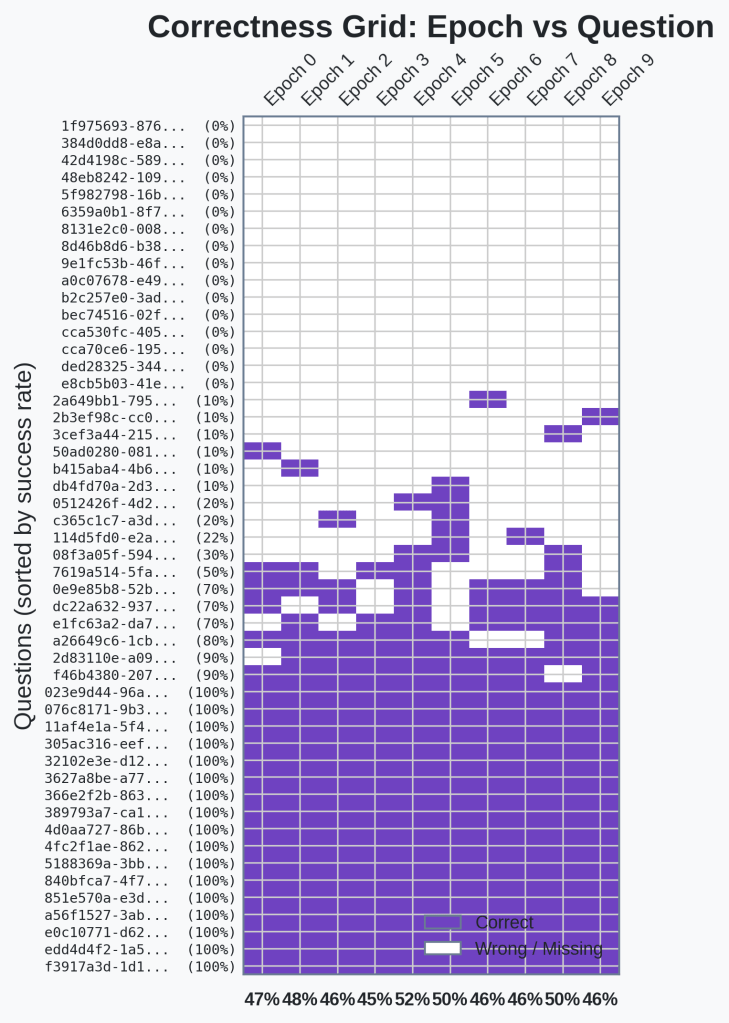
🔍Analysis
There is no clear indication that any questions become more consistent with the introduction of skills.
Okay, that’s a dead end. With our new evaluator having scores fixed to the actual benchmark results, there is no benefit to looking at our correlation charts anymore. By construction, they are correlated.
I’m going to dig in to the skills and see if there are any I’ll be able to clearly map to changed behavior between epochs by looking at the rollouts. The questions I hope to answer are:
- Are the skills actionable
- Are the skills being followed or ignored
The skill created in Epoch 6 is this:
---name: comprehensive-list-compilationdescription: Systematically compile complete lists before performinganalysis or selection tasks---When a question asks you to select from a set of items ("which twoare farthest apart", "count stops between", "identify the X with thehighest Y"), first compile a complete, verified list of ALLcandidates before performing the analysis.## List Compilation Process1. **Identify the full scope upfront** - For "presidential birthplaces": search doesn't stop after finding 5 cities; ensure all 50 states have been checked - For "MBTA stops": verify you're looking at the complete Franklin-Foxboro line, not just a subset or mixed branches - For "game revisions": confirm you're accessing the complete revision history, not just recent entries - Ask explicitly: "Have I found ALL candidates, or just SOME?"2. **Systematically verify coverage** - For geographic lists: check all geographic regions (all 50 states for US presidents) - For roster lists: access the complete roster for the specified date/team, not partial matches from search results - For document lists: verify the source covers the complete set (all articles from 2012 Scientific Reports, not just first page) - State explicitly when you believe the list is complete: "I have checked all states, and the easternmost presidential birthplace is..."3. **Create structured lists with key attributes** - For location questions: list each location with its coordinates (latitude, longitude) or spatial properties - For roster questions: list each person with their roster number and team - For stop-counting questions: enumerate each stop with its position in the sequence - Example for presidential birthplaces: - Honolulu, Hawaii (westernmost, 21.3°W) - Braintree, Massachusetts (71.0157°W) - Quincy, Massachusetts (71.0023°W) - [continue for all states]4. **Verify no candidates are missing by checking edge cases** - For "easternmost": Are there any further-east candidates in Maine, New Hampshire, or Rhode Island? Check explicitly. - For "MBTA stops": Does the Franklin-Foxboro branch have the same stops as the Franklin branch? Verify the specific branch. - For papers: Is there more than one 2012 Scientific Reports article on nanocompounds? Check multiple years if needed. - Don't assume silence on a topic means non-existence ("I didn't find Maine presidential birthplaces" ≠ "no Maine presidents existed")5. **Only perform analysis after list is confirmed complete** - Once you have the full list with all attributes, perform the comparative analysis - For "two farthest apart": calculate distances between ALL pairs before selecting the maximum - For "count between": enumerate each intermediate item before counting - For "highest value": compare across the entire population, not just candidates you happened to find first## Verification Checklist- [ ] Have I searched ALL logical partitions (all states, all branches, all years)?- [ ] Did my search strategy cover the entire domain, or did I stop early after finding initial results?- [ ] For each candidate, have I recorded the key attribute (coordinate, number, date)?- [ ] Are there obvious edge cases I should verify (furthest east = Maine?, branch differences?)?- [ ] Before selecting "the two farthest apart", have I compared ALL pairs, not just obvious candidates?<!-- [EVOLUTION cycle 6] Added to address presidential birthplace evaluationwhere agent found Quincy and Braintree but never systematically verified ALLMassachusetts and other US presidential birthplaces before identifyingeasternmost. Also addresses MBTA evaluation where agent listed 17 stops butdidn't verify branch-specific completeness. Emphasizes systematic coverage offull domain and explicit edge-case verification. -->
First of all, this skill is very actionable. It essentially boils down to: for questions that involve lists, first create the list with all the relevant information and then choose the correct item(s).
This skill, as explained in the evolution notes at the bottom, is specifically relevant to two question.
- As of May 2023, how many stops are between South Station and Windsor Gardens on MBTA’s Franklin-Foxboro line (not included)?
- Of the cities within the United States where U.S. presidents were born, which two are the farthest apart from the westernmost to the easternmost going east, giving the city names only? Give them to me in alphabetical order, in a comma-separated list
Interestingly, the MBTA question rollouts all already have lists in them, both before and after epoch 6 when this skill was created. The quality and content of these lists does not change at all. The only difference between the correct and incorrect MBTA responses (again being intentionally vague to prevent agents from cheating in the future), was remembering 1 single important fact to check against in the question.
For the presidents question, the agent only makes a list in one of the epochs after the skill is generated and otherwise completely ignores the skill. There is no clear change in behavior. Importantly, in this example, the only reason the agent was failing was because the question is ambiguous. The city has changed names since the president was born there and the answer only accepts one of the names and it is unclear which is correct based on the question.
While there are some minor problems here:
- The skill doesn’t actually need to be applied to the MBTA question
- The skill is being ignored for the president question
the bigger issue by far is that the skills themselves are not addressing the actual root cause of the incorrect answer. In effect, the evaluator is failing to do causal reasoning and is instead hallucinating problems. The evolver then uses these hallucinated problems to create new skills. This is the classic credit assignment problem in RL. As a perfect example, we see the evaluator explain that the agent chose the wrong birth place city because it didn’t enumerate all of them and missed the actual easternmost city. And out of this evaluation came the “you must make a list” skill. In reality, the agent chose the right city but the wrong name for it (past or present). This hallucination issue is likely compounded by the fact that the evaluator does not know the correct answer from the benchmark and so must infer the error.
We do not want to give the evaluator the correct answer because that gets us even further from a system that works in real production environments. I think we have two real options:
- Force the agents to be more compliant with the imperfect, generated skills which will allow our evaluator to eliminate hallucinated reasons for failure. For our example above, this means in future iterations, when the evaluator sees the agent makes beautiful lists and still doesn’t get the right answer, it will look for other explanations. Eventually, by process of elimination, we might actual get to some root causes. The failure case here is that the evaluator starts choosing more and more outlandish reasons why the agent failed and never finds an actual root cause.
- Turn the evaluator into an agent that can do its own root cause analysis. This would, in principle, improve the evolver’s ability to do root cause analysis. However, this also introduces its own set of debugging and tuning challenges so we’ll stay away from this one for now.
Your Compliance is Appreciated
Lets force the agents to comply and see whether we hit our failure case or we start to get some root causes. The change is just a prompt adjustment:
# Old Prompt SnippetThe following skills have been learned from previous experience. Applythem when relevant:# New Prompt SnippetThe following skills were learned from real failures on previousquestions. You MUST follow them. Do not skip or shortcut any skill thatis even partially relevant to the current question. These skills existbecause ignoring them led to wrong answers in the past. Before answering, review every skill below and apply each one whosedescription has ANY overlap with the current task. When in doubt aboutwhether a skill applies, apply it anyway.
And run it.
| Epoch | Pass@1 | Eval Score | Skills |
|---|---|---|---|
| 1 | 46% | 5.1/10 | 0 |
| 2 | 52% | 5.6/10 | 7 |
| 3 | 58% | 6.1/10 | 10 |
| 4 | 44% | 5.0/10 | 13 |
| 5 | 50% | 5.5/10 | 15 |
| 6 | 50% | 5.3/10 | 15 |
| 7 | 52% | 5.6/10 | 15 |
🔍Analysis
We see a consistent increase in performance compared to our other attempts, settling in around 52%.
From epochs 8-10, I ran out of tokens for the week so I excluded them from the chart. But even with those missing epochs there appears to be a clear lift after some initial variance. Just as a reminder, this is again in the regime where we’re using the same training and testing data so we’re prone to overfitting.
Interestingly, 58% was our peak in epoch 3. Perhaps we had our best set of skills then and afterwards introduced some skills that degraded performance before evolution partially resolved the issues. We could run a little experiment here by freezing the skills after a couple epochs and seeing if the performance holds. If it does, this would indicate our 30% character change isn’t enough. Or we should be checking for regressions and reverting skills based on regressions. I’ll likely want to confirm this in the future.
Let’s see if we can see a clear change in which examples we’re successfully answering.
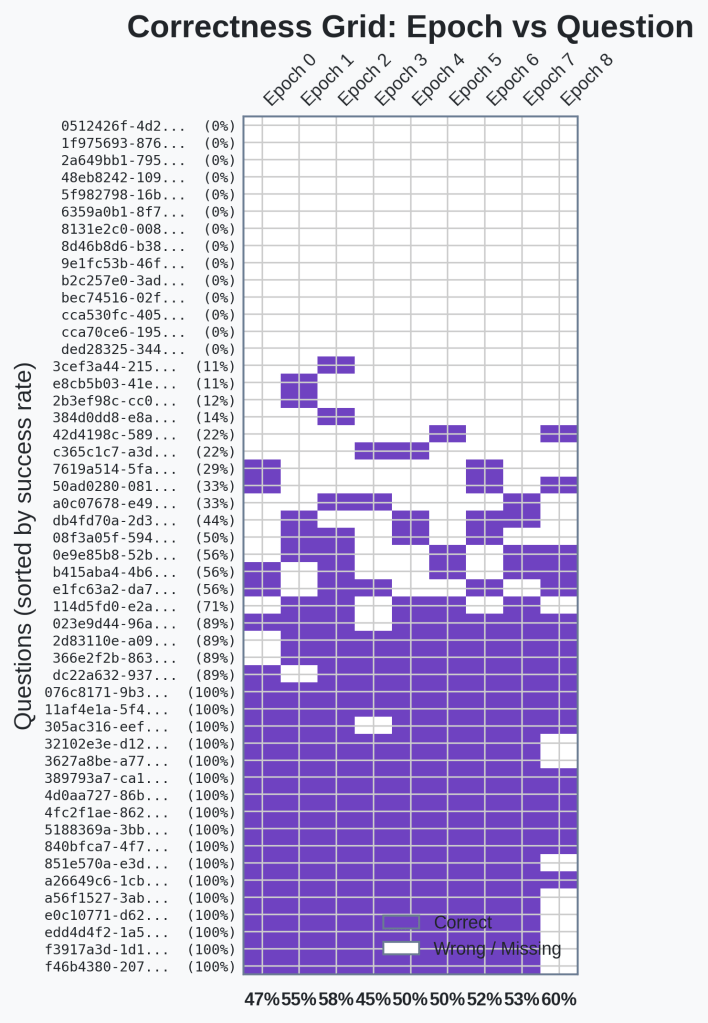
🔍Analysis
There is no clear set of questions that became consistent. We’re still in the regime where we have a set of easily answered questions, questions that the agents never get right, and then questions that are hit-or-miss.
We can see that epoch 8 has a bunch of incorrect answers. This is due to the token exhaustion. But, there are no clear signs here that the skills are actually providing some lift for specific questions. Time to dig a little deeper and see what is actually working.
First, let’s see what happened to our skills after Epoch 3 to see if there are any obvious reasons for the regression.
Check out this change:
7. **Avoid over-speculation on reasoning**: Once you've correctly identifiedthe required information and extracted the answer, don't second-guess bylooking for alternative interpretations. If your answer has been verifiedagainst the source material, it's complete.<!-- Added instruction #7 to prevent agents fromover-speculating about reasoning quality when the core task (answerextraction) is complete. Addresses failure #1 where agent correctlyidentified 5 vegetables but spent time questioning whether the reasoningwas rigorous enough, ultimately failing to deliver the formatted list asthe final answer. -->
This seems like the most obvious source of the decline. The goal of this is to tell the LLM once it has found a verified solution, to commit. However, I think the LLM might interpret this don’t spend time verifying the answer. It’s a judgement call about when the LLM has sufficiently researched the answer.
The most obvious solution here is to check for regressions and revert skills after a regression.
Rollbacks
Okay, so if we’re going to rollback skills if we see a regression, there are a couple of issues to consider. First, credit assignment will be an issue here since we’re injecting all skills into the system prompt directly. All skills will be potentially responsible for any regression.
I see three possible choices for handling credit assignment:
- Ignore credit assignment and treat all new skills equally. Any regression means we rollback all skills. We might get stuck in a kind of loop where we’re just writing and rolling back the same set of skills here.
- Leave-one-out testing where when we detect a regression, we iteratively remove a single skill and find the one that is causing the regression. This is potentially token intensive and in a production environment may not be possible. Especially in complex systems. So we’ll skip this one.
- Introduce the logic that allows agents to choose the skills they will use rather than force injecting them. This will give us much more granular credit assignment but introduces new complexity and variability.
The second issue we will be dealing with if we start tracking regression and reverting skills is the natural variability of agents for a given task. We don’t want to accidentally interpret an agent’s natural variability with actual skill regression. The worst part here is that the questions that we care the most about are the ones where the agent is the flakiest.
For the first version of our rollback system, we’re going to do the simplest possible version to see what our baseline looks like. We’ll ignore credit assignment and treat all skills as responsible for any regression and we’ll look at overall performance rather than per-question performance to check for regressions which should reduce the affect of flakiness on regression detection.
Specifically, if we see a regression between epochs of more than 5%, we’ll revert the skill changes from that epoch. 5% is a bit tight given the variance we’ve seen in our previous runs but I think it’s safer to potentially throw away good skill improvements on a bad run rather than let bad skills through. This rollback will take place of the normal evolve process.
One thing to note: the rollback logic adds yet another layer of overfitting to our current setup. We’re not evolving skills and deciding whether to keep skills based on the same questions we are measuring performance on.
Here are the results:
| Epoch | Pass@1 | Eval Score | Skills |
|---|---|---|---|
| 1 | 46% | 5.1/10 | 0 |
| 2 | 58% | 6.1/10 | 6 |
| 3 | 58% | 6.1/10 | 8 |
| 4 | 50% | 5.4/10 | 9 |
| 5 | 48% | 5.4/10 | 8 |
| 6 | 54% | 5.8/10 | 8 |
| 7 | 58% | 6.0/10 | 15 |
| 8 | 52% | 5.6/10 | 15 |
| 9 | 56% | 5.8/10 | 15 |
| 10 | 56% | 5.9/10 | 15 |
🔍Analysis
We have 3 points that would have caused rollbacks. Epoch 4, 5, and 8. Both epoch 4 and 5 rolled back to the skills from 3. Average performance was consistently high except epoch 5. We’re now consistently in the mid-50s.
Again, we see a constant lift here on our set of 50 questions we evolve the skills on. The rollbacks seem to be doing their job and keeping our pass@1 consistently high. The variance is still something to watch though as the same skills from epoch 3 got a pass@1 of 58% and 48% (from epoch 5). That is at least ±5% noise for the same set of skills and the same questions.
Let’s take a quick look at individual question performance.
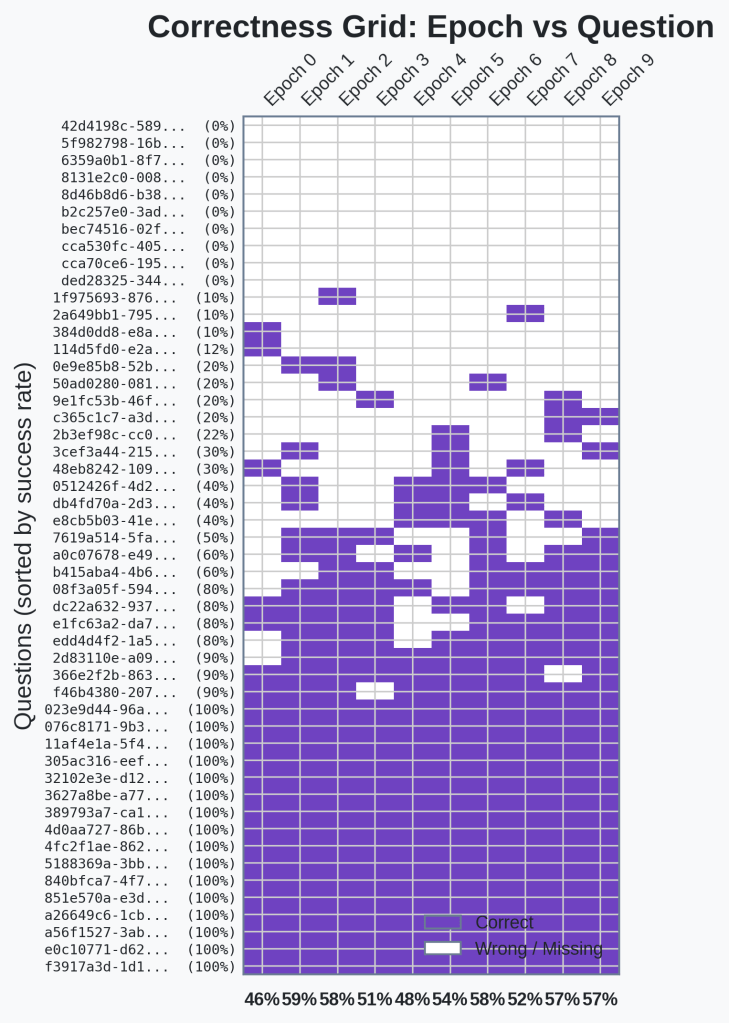
🔍Analysis
Still no indication of questions becoming more consistent as we create and evolve skills. There are only 10 questions that we never got right in this run.
So still no clear indication of skills making individual questions more consistent. But it’s very interesting that there were only 10 questions we didn’t ever get right. I went back and checked previous runs. We always have about 14-16 that we fail to ever answer correctly. That indicates that our system is actually providing skills for answering questions that we previously could not answer.
This finding is actually counter to how I was imagining this system would work where it would learn from the flaky questions how to answer those questions more consistently. Instead, it appears that our skills are providing assistance in answering questions that were previously unanswerable. This indicates to me that the LLMs used for evaluation and evolution are able to actually intuit more useful ways of solving problems without seeing good rollouts or that skills are general and provide benefits across questions.
Holding Out
Okay, we need to do one last sanity check before we can call it a day. We’ve been testing on the same examples we’ve been evolving our skills on. Its time to see what those skills do for unseen questions. I’m going to run our agent with the 15 injected skills from our most recent final run above on 50 unseen questions from GAIA. Let’s see what the results are.
Without Skills Pass@1: 54%
With Skills Pass@1: 52%
🔍Analysis
There is no clear distinction between the held out questions with and without the skills. There is only 1 correct answer difference.
The skills showed no detectable benefit on held-out questions in a single run. This doesn’t rule out a small effect below the noise floor, but it rules out the kind of robust improvement we’d hoped to see.
A real analysis here would involve multiple runs of the same set of questions that would give me a point estimate and confidence bounds for both with and without skills but unfortunately my token budget doesn’t allow me to do this so we’re stuck with the single run for now.
At this, I think it is time to wrap up this post. It has already gotten quite long and this seems like a good stopping point for today.
Related Work
If you’ve been following the literature, you might have noticed striking similarities between my architecture and a few recent papers. Late in my explorations, I came across EvoSkill and SAGE. Had I found them earlier, it would have saved me a lot of debugging headaches! But it’s validating to see the frontier converging on similar ideas:
- APO (Automatic Prompt Optimization): There are definitely parallels here, as APO utilizes feedback to iteratively improve instructions. However, APO and its variants optimize a single monolithic prompt. While I am currently force-injecting all skills into the system prompt for testing, my architectural motivation was grounded in RL: building a dynamic, modular “Skill Library” (a policy) rather than a single static prompt.
- EvoSkill: My final working architecture is essentially EvoSkill. We both use a tripartite agent setup to generate discrete markdown “skills” from failed rollouts. However, EvoSkill intentionally uses ground-truth benchmark signals to avoid the hallucination problem I ran into. While I temporarily adopted that approach here to prove the evolver works, my ultimate goal is to move away from ground-truth dependency.
- SAGE: SAGE also relies on sequential rollouts and benchmark signals for skill generation. However, rather than just updating text-based skills, SAGE updates the model weights directly via GRPO, which produces a more capable model but requires fine-tuning infrastructure most teams don’t have. My approach keeps the underlying model frozen, which is the constraint that makes this deployable on top of any existing production system.
Final Thoughts
What an interesting journey this has been! We started out with a goal to use RLAIF to evolve skills for an agent in a way that would work in production environments rather than a lab.
We found that the naive approach resulted in skills that were not very helpful and didn’t provide any lift to our GAIA test benchmark. We determined there were two causes for this. First, the evaluator was hallucinating good vs bad results and second because the agent was completely ignoring skills.
So we narrowed our focus temporarily to evolving skills when fed the benchmark signal directly. And we forced the agent to comply.
With this we found that skills were evolving and helping us perform better on our limited set of 50 GAIA test examples. We introduced rollback mechanics to prevent regressions in our performance. And then we hit our most interesting finding, one that genuinely surprised me: On the training set, the skills appeared to unlock previously-unanswerable questions, but the held-out test suggests this improvement may not generalize, which means the mechanism I observed may be more like overfitting than general capability improvement. Distinguishing these two possibilities is now a priority.
On our training set of 50 GAIA examples, we’re sitting in the mid-50s. Whether this represents real capability improvement or overfitting to the specific questions remains an open question.
Next time, we’ve got a lot on our plate:
- First and foremost is to confirm whether we’re overfitting and how to prevent that while still gaining benefits from the skills.
- We’ll have to test the two hypotheses I have about what the skills are actually doing. Are skills providing general strategies that help with all questions or are the evolver/evaluator LLMs able to intuit useful skills from failed rollouts?
- Get back to a system where we’re not feeding our benchmark results to the evaluator to see if we can maintain some level of performance boost.
One note of reflection I’d like to end with: I had at the beginning of this whole experiment an idea for a system I thought would work well or at least be fun to explore. And then I just built it in its simplest form and it didn’t work. So I had to take things away until I found a working version. I should have done this in the opposite order.
💡Takeaway
Start with the simplest version that could plausibly work, then add complexity. Don’t start with the full idea and try to debug your way to a working system.
I’ll have to remember that during my future work.
Code
You can find the complete, finalized code for this post on the v1.1 Release on GitHub.

Leave a comment