Reinforcement learning is a fickle beast. One minute, you’re on top of the world, just having discovered a novel algorithm that performs amazingly well, the next you’re down in the dumps, your algorithm shattered, and your agent barely functioning. Today is that story.
Where We Left Off
Last time, we deconstructed our “helpful bug” and discovered a novel TD-Error definition that helped to manage the bias of the critic during training. It worked really, really well for MinAtar Breakout. For the past two full weeks, I’ve been testing whether tau-regularization was a general solution or whether it only worked well for Breakout.
Then, the Redditor bci-hacker had a very exciting suggestion. Why not make the tau value learnable! That sounded very interesting and I was ready to go try it out! Another very interesting investigation was in my future, for sure.
But then, came the bomb drop. Redditor JumboShrimpWithaLimp found another bug in my code! So, that leaves us in an interesting situation. Was the tau-regularization just correcting another bug we had in our system? Is tau-regularization still helpful? How will my agent perform once we fix the bug? We’ll find out today and hopefully learn some interesting things in the process!
What’s Bugging You?
Okay, sooo… what was the bug? Essentially, my critic was trying to learn a strange combination of rewards and advantages, rather than the true returns. Oops.
For those who care about the specifics, let’s walk through it. If you’re not a fan of equations, feel free to skip ahead.
The standard PPO critic loss is a simple Mean Squared Error: Loss = (Target - Prediction)².
The Prediction is our critic’s value estimate:

The Target is the actual discounted return the agent received from that state:
So the correct loss function is:

Now, here’s what my buggy code was doing. My target was incorrectly set to reward + advantage. Let’s expand that out to see how strange the learning signal was:
Buggy Target =

Since 
Buggy Target =

Instead of learning to predict the true return (
I’m surprised the agent learned a useful policy at all from that!
Hit The Reset Button
Okay. It’s an easy bug to fix. I’ve replaced the incorrect loss function with the correct implementation. Let’s turn off our tau-normalization which may not be helpful anymore and see how our agent does.
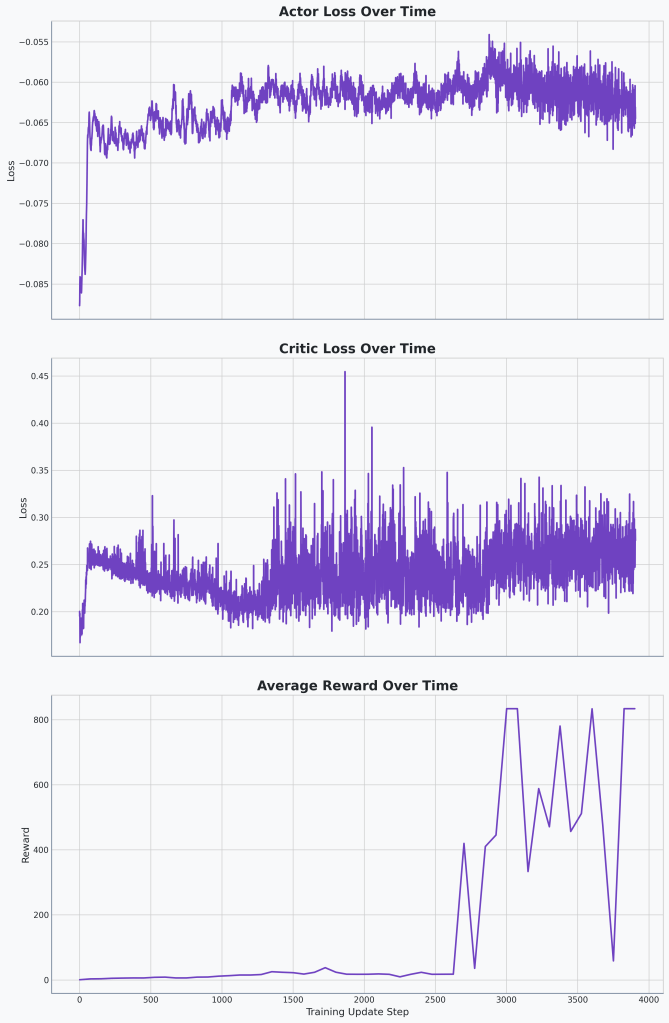
🔍Analysis
Things look pretty stable here. We’re not outperforming our old method but even without the tau-normalization we’re getting really good results.
So the final rewards were 834 min, max, median, and average episodic rewards across 1024 unique iterations of the game. Weird that we’re hitting 834 for all of them. Unless that’s a new maximum we’ve hit at 10,000 environment steps. But this is slightly above our tau-normalization agent that had the critic loss bug.
What’s the Comp?
So, the next question is a big one: was our tau-regularization just compensating for our incorrect critic loss?
It’s going to be difficult to test if the technique still improves our agent’s performance, since our new bug-fixed baseline is already hitting the environment’s maximum score. But we can perform a crucial sanity check: does it break what’s already working?
This leads to a new hypothesis:
🤔Hypothesis
If we apply tau-regularization to our new, perfectly-performing agent, the performance will not decrease, because the technique provides a fundamental stability benefit that is independent of other bugs.
Okay, perfect. This gives us a clear test. Let’s turn our tau-regularization back on and see what happens:
- If performance stays at the maximum, our hypothesis is supported.
- If performance gets worse, it would suggest the technique’s previous benefit was just a fluke—an artifact of interacting with the other bug.
Let’s check it out!
| Tau | Median Episodic Reward | Mean Episodic Reward | Min Episodic Reward | Max Episodic Reward |
|---|---|---|---|---|
| 0 | 834 | 834 | 834 | 834 |
| 0.1 | 55 | 83.77 | 55 | 115 |
| 0.15 | 635 | 644.59 | 635 | 655 |
| 0.2 | 742 | 740.56 | 739 | 742 |
| 0.3 | 7 | 7 | 7 | 7 |
🔍Analysis
Our baseline, with tau = 0, gets the best performance of all of these with the second closes being significantly worse.
Well, there it is. The data is unambiguous: on a correctly implemented agent, tau-regularization is not only unhelpful, it’s actively harmful. I think we can close the book on that chapter. The ‘helpful bug’ was really just compensating for another, deeper bug. Turns out two wrongs sometimes do make a right.
Final Word
Well we definitely achieved the goal we set out to at the beginning of this Breakout journey of tuning a very powerful Breakout agent. I’ve learned quite a bit along the way. I started as someone who would randomly change different hyperparameters in the hopes of stumbling into a working agent. These last few months have taught me a much more principled, intentional approach.
What takeaways can we take from the tau-normalization work? Well, I’ve said it before but I guess it’s going to take me a few times to learn.
💡Takeaway
Be vigilant for bugs, not just when your agent is struggling, but especially when it seems to be performing unexpectedly well.
I think this is going to be the end of the Breakout saga. My plan initially was to code a bunch of baselines that I can use for experimentation but given that I’m already maxing out rewards in Breakout, I’m wondering how useful these MinAtar environments will actually be as baselines for testing different algorithms.
My goal is to tackle problems where the solutions aren’t already known and where the impact of new techniques can be clearly measured. That’s why, for my next saga, I’m going to pivot to one of the most exciting and challenging frontiers in AI: using RL to fine-tune open-source LLMs. It’s a domain with a massive landscape for exploration, and I’m excited to start from scratch. At the very least, it will be an interesting ride!
Code
You can find the complete, finalized code for this post on the v1.7 Release on GitHub.

Leave a comment